El Xatbot · Evolució Arquitectural · WebScraping
Del sistema manual al
WebScraping Automàtic
Millora estructural profunda del Xatbot: canvi de paradigma d’una arquitectura estàtica basada en JSON a un sistema dinàmic de WebScraping recursiu integrat directament amb el model d’IA Gemini.
Canvi de paradigma
Introducció
Aquesta evolució suposa un canvi de paradigma: s’ha passat d’un sistema estàtic basat en dades manuals (JSON) a una arquitectura dinàmica basada en WebScraping recursiu, amb integració directa amb un model d’IA (Gemini). Això transforma el sistema en un ecosistema més autònom, escalable i proper a una arquitectura professional real.
Arquitectura anterior: sistema JSON
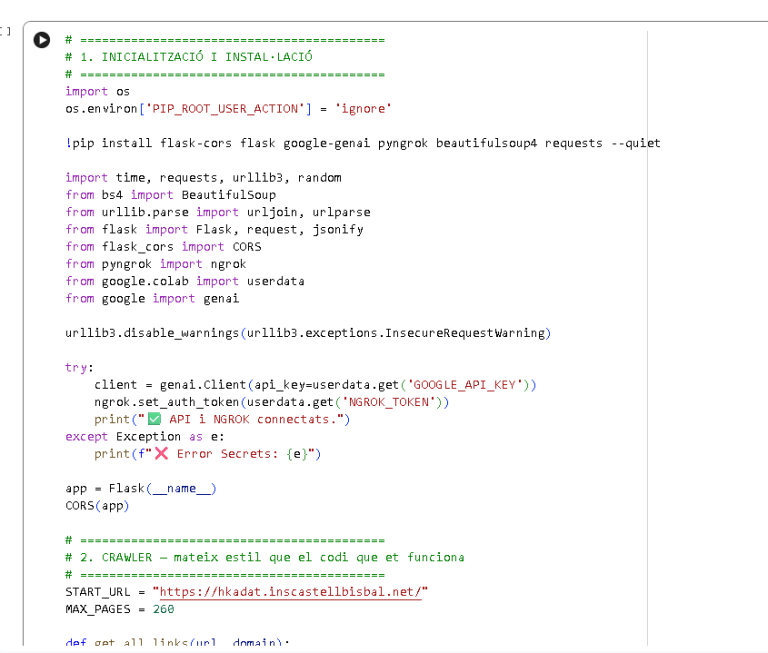
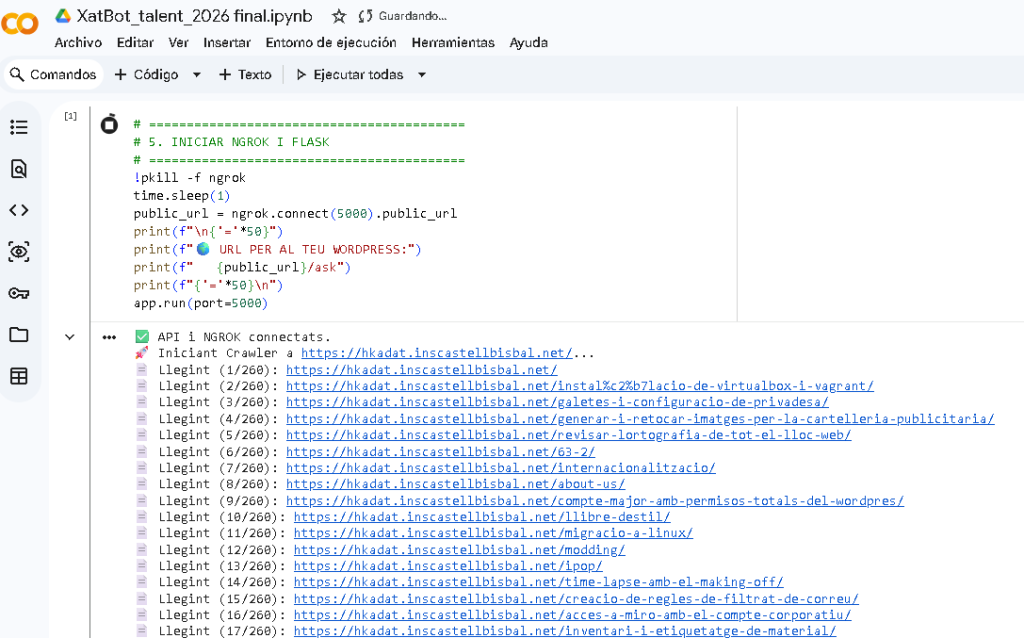
Crawler recursiu: adquisició de dades
Flux de funcionament del crawler
El crawler actua com un mòdul d’adquisició automàtica de dades, responsable de recórrer el portafolis i construir una representació completa del seu contingut.
def crawl_website(base_url, max_pages=20):
visited = set()
content = []
def scrape_page(url):
if url in visited or len(visited) >= max_pages:
return
visited.add(url)
try:
response = requests.get(url, timeout=8)
soup = BeautifulSoup(response.text, 'html.parser')
# Extracció de text net (sense navegació ni botons)
text = soup.get_text(separator=' ', strip=True)
content.append(text)
# Recorre els enllaços interns recursivament
for link in soup.find_all('a', href=True):
href = link['href']
if base_url in href:
scrape_page(href)
except Exception as e:
print(f"Error: {e}") # Continua sense trencar el sistema
scrape_page(base_url)
return ' '.join(content)
BeautifulSoup: filtratge i neteja
Capa de processament del contingut HTML
Per garantir la qualitat de les dades, s’utilitza BeautifulSoup com a capa de processament i neteja del contingut HTML. Aquesta etapa és fonamental perquè assegura que el model d’IA no rebi soroll (noise), sinó dades estructurades i rellevants.
Robustesa: gestió d’errors
try:
# Petició amb timeout de 8 segons
response = requests.get(url, timeout=8)
response.raise_for_status()
# Processament del contingut
soup = BeautifulSoup(response.text, 'html.parser')
text = soup.get_text(separator=' ', strip=True)
except requests.exceptions.Timeout:
print(f"Timeout: {url} — continuant...")
except requests.exceptions.ConnectionError:
print(f"Error de connexió: {url} — continuant...")
except Exception as e:
print(f"Error inesperat: {e}")
# El sistema continua sense interrompre's
Integració FrontEnd–BackEnd–IA
Arquitectura de capes
Un cop finalitzat el WebScraping, el sistema genera una variable de text estructurat que flueix a través de les capes de l’arquitectura fins arribar a l’usuari final.
Problemes reals resolts
Durant la integració s’han resolt problemes reals: errors de CORS en la comunicació entre client i servidor, filtrat de recursos no compatibles (imatges, PDFs), i optimització del flux de dades cap al model d’IA.
Seguretat: protecció de les API keys
Justificació global: arquitectura de sistema
Conceptes d’enginyeria de software introduïts
Evidències del sistema
Conclusions finals
Aquesta evolució del Xatbot representa una transició cap a una arquitectura molt més propera a sistemes professionals reals. El canvi de sistema manual i estàtic a sistema automatitzat, dinàmic i escalable és el punt central d’aquesta millora.
El projecte no només millora el rendiment del Xatbot, sinó que demostra la comprensió de principis fonamentals d’arquitectura de sistemes moderns: separació de responsabilitats, automatització del flux de dades, robustesa davant errors, seguretat de credencials i escalabilitat.